Ольга Мегорская, руководитель службы асессоров, в докладе «Качество поиска: экспертные оценки и исследование пользовательского поведения» рассказывает о службе качества поиска, о том, чем занимается группа.
Оценка качества поиска. Для чего нужно оценивать качество выдачи? Как известно, в компании Яндекс работают многие разработчики, предлагающие новые «фичи», новые алгоритмы поиска. У разработчика есть десяток любимых запросов, на которых он проверяет свой алгоритм, и все классно работает. Но любой алгоритм требует объективной и корректной оценки со стороны. И не на десяти любимых запросов, а на довольно большой выборке случайных запросов. Именно этим занимаются асессоры - они оценивают качество поиска с точки зрения пользователя. Если «фича», новый алгоритм действительно улучшает выдачу по одному классу, надо следить, чтобы «не уронить» все остальное.

Что нужно для того, чтобы оценить качество поиска с точки зрения пользователя?
- пользовательские оценки качества выдачи;
- формализованные метрики качества;
- человеческое, а не машинное понимание пользователя.
Асессоры - обычные люди. Они присутствуют в каждом регионе. В компании Яндекс всегда стремятся учитывать оценки местных - региональных - пользователей, потому что именно они как никто другой понимают местную специфику Интернета, что хотят люди не только в России, и конечно же большую роль играет знание языка выдачи. К примеру, команда Яндекса работает в Казахстане несколько лет.
Как работают асессоры?
- выбирают случайные запросы из потока данных;
- оценивают документы/страницы, найденные по запросам;
- выносят оценки качества выдачи.
Асессоры работают удаленно, находясь дома. Они получают случайно выбранные запросы и реального общего потока запросов. По этим запросам выкачивают выдачу и отдают асессору. Они оценивают, насколько хороши те или иные документы и отвечают ли они реальным запросам. Оценивание ведется по специальной шкале релевантности.
Шкала релевантности выглядит так:
- оценка vital - для тех сайтов, которые жизненно необходимы, однозначно должны быть на первых местах;

Съешьте это немедленно!
оценка useful - получен авторитетный, полный ответ;
Берите! Полезный продукт!
оценка relevant «плюс» - в целом отвечает на запрос;
Ловите нужное!
оценка relevant «минус» - имеет отношение к запросу пользователя, но отвечает не в полной мере;
Яблочное?
оценка irrelevant - результат выдачи не отвечает на запрос.

Какое яблоко без «клубнички»...
В группу vital обязательно входят официальные сайты, которые никак нельзя пропускать. В группе useful состоят авторитетные, известные источники. Релевантные документы в некоторых случаях могут напрямую не отвечать на запрос, но могут дать представление о предмете запроса, имеют отношение к запросу. Видя в выдаче один релевантный документ, пользователь вряд ли сможет получить полный ответ на свой запрос, но, видя несколько релевантных документов, он получает более-менее широкое представление о предмете запроса.
Для чего используются оценки, собранные асессорами?
- для тонкой подстройки поисковых алгоритмов;
- для определения оценки качества поиска.
Это две одни из самых важных вещей в поиске.
Настройка поиска.
Робот обучается различать «хорошие» и «плохие» страницы. К примеру, есть две неких группы - яблоки и груши со своим набором качеств: цвет, вкус и форма.

Роботу предстоит разделить большой объем фруктов на яблоки и груши. Разработчик дает роботу обучающие подмножества - набор дополнительных качеств. Робот ищет закономерности, характеризующие тот или иной фрукт. Все зеленое, кислое и круглое, группируется в «яблоки», а все овальное, сладкое и красное - в «груши».
Когда в дальнейшем робот берет из корзины непонятный фрукт, он сразу может оценить его по типу признаков. И все идет хорошо, пока в корзине с фруктами не появляется некий красный вытянутый кислый предмет - то ли яблоко, то ли груша.

Тогда робот начинает изучать предмет глубже, например, по ДНК. Поэтому, чтобы не сталкиваться с проблемами при оценке ресурса, робот обучается множественным оценкам, и это множество составляется людьми.
Аналогичный процесс идет с оценкой релевантности документов.
- робот располагает своим наборов поисковых алгоритмов;
- асессоры дают свои оценки;
- в Вебе робот ищет суммарные закономерности;
- в случае затруднения, робот подключает для оценки следующие факторы: в документе Х есть запросы, на документ группы «Х» кликают и на него ссылаются другие ресурсы Веба. Вероятно, документ группы «Х» релевантен.
Итак, робот обходит Веб, автоматически собирает признаки документов - тексты, запросы, рядом запросы или разбиты по тексту, в заголовке и в теле текста, кликовые признаки - насколько часто кликают по ссылкам на тот или иной документ, если есть линковые факторы, то по каким запросам ссылаются на этот документ, и пр. Это все робот собирает автоматически.
С другой стороны, есть оценки асессоров. Асессоры ничего не знают про факторы, они просто смотрят на документ с точки зрения пользователя - хороший это ответ на запрос или нет. Робот ищет закономерности. Для любого неоцененного документа в Сети робот ищет знакомые факторы. Возвращаясь к овальному красному кислому яблоку, можно сказать, что для оценки документа группы «Х» нужно много факторов. Поэтому очень много людей непосредственно занимаются тем, что изобретают и предлагают разные факторы оценки релевантности. Обучение робота идет на реальных примерах - на реальном потоке запросов. Этот поток запросов асессорам никто не продает, его никто не придумывает, берутся только реальные запросы, которые приходят в Яндекс каждый день.
Метрики оценки качества поиска
Одной из рабочих, базовых метрик является метрика Pfound - «вероятность пользователя найти ответ».
Пример Pfound. Есть две выдачи в 2 столбцах для сравнения.
|
1 столбец |
2 столбец |
|
vital |
vital |
|
relevant «плюс» |
relevant «плюс» |
|
relevant «плюс» |
relevant «минус» |
|
relevant «минус» |
relevant «плюс» |
|
irrelevant |
irrelevant |
Как вы думаете, какая из этих выдач лучше? Мы считаем, что левая метрика лучше, потому что более хорошие документы скомпонованы выше.
Метрика Pfound выстраивается на такой схеме пользовательского поведения:
Выдвигается гипотеза поиска
Пользователь продвигается сверху вниз и просматривает все документы, один за одним.
Пользователь останавливается, если: нашел, устал.
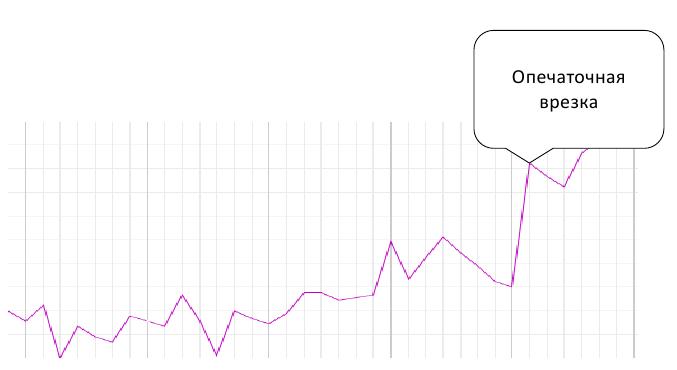
Недавно была внедрена так называемся «опечаточная врезка», был приятный хороший скачок, никто не понял, почему, а мы знаем, почему поиск сразу выдал гораздо большее число документов. «Опечаточная врезка» - это изменение алгоритма обработки запросов с опечатками.
Разнообразие выдачи - любопытная вещь, и бывает разнообразие нескольких типов
Например, под словом «наполеон» ищут разные объекты - императора и торт, причем торт ищут чаще в связи с наступлением праздников

Или другой пример - ищут объект, но связывают с ним разные потребности. Запрос - название фильма. Если фильм старый, его чаще хотят скачать или смотреть онлайн, про новые фильмы, которые идут в прокате, ищут трейлеры, рецензии, о будущих фильмах нужна более общая информация, скачать никто не пытается.
Эти примеры говорят, как сложно роботу понимать то, что хотят пользователи. Невозможно без дополнительных объективных данных понять, что у пользователя в голове, когда он отправляет запрос. Поэтому ведется исследование пользовательского поведения:
- сессии отдельного пользователя;
- переформулировки своего запроса и клики на какие сайты были сделаны;
- эксперименты на выдаче - это использование экспериментального алгоритма на неком числе пользователей - n%; выявление доли некликнутых результатов, если пользователь нашел ответ прямо в сниппете - маленькой информации о сайте, определение позиции первого клика - насколько выше оказался нужный документ, и другие метрики, выявляющие, хороший это был эксперимент или нет. Кстати, по поводу снипеттов. Когда выкатили алгоритм, индексирующий сниппеты с информацией о компании - телефоны, эл.адрес, в Яндекс стали звонить расстроенные веб-мастера с обидой - почему на мой сайт перестали кликать, если позиции его не упали. В выдаче все хорошо, а заходов нет. И получилось так, что с точки зрения пользователя мы сделали все хорошо - он сразу все видит на странице выдачи, а результаты по продвижению сайта в глазах заказчика упали.
- классификация запросов.
Выделение тематик запросов.
- отбор интересующих групп пользователей;
- составление автоматического классификатора запросов;
- изучение результатов - анализ распределения разных тематик поисковых запросов для неодинаковых групп пользователей.
К примеру, можно выделить запросы, которые больше интересуют владельцев «андроидов» и владельцев «айфонов».

Владельцев «андроидов» больше интересуют тематики: информатика и информационные системы, эротические игры, электронная музыка, архивы программ, дачи и коттеджи, unix, экранные заставки, приложения, веб-программирование, операционные системы, форумы, чаты, софт, компьютерные игры, русификаторы, трейлеры, патчи.

Владельцев «айфонов», и это довольно любопытно, чаще интересуют: прически и салоны красоты, алкогольные напитки, свадьбы, тосты и сценарии, литература, зарубежная проза, боди и нейл-арт, доставка цветов, кондитерские изделия, лошади, конный спорт, бизнес-образование, визы и паспорта, подготовка водителей, обувь.
Это не значит, что все владельцы «айфонов» ищут салоны красоты, но можно сделать предположения о типичности запросов и использовать в маркетинговых целях.
